
public class WhyHashSetSort {
public static void main(String[] args) {
Set<Integer> hashSet = new HashSet<>();
hashSet.add(4);
hashSet.add(3);
hashSet.add(1);
hashSet.add(2);
System.out.println(hashSet);
}
}일전에 내가 알고 있던 HashSet 중복을 허용하지 않고 정렬을 지원하지 않는다고 알고 있었다.
하나 위의 코드를 실행했더니 아래와 같이 정렬된 결과가 나온다.

이유가 무엇인지에 대해서 내부 라이브러리 소스를 통해서 확인해보도록 하자!
일단 결론부터 말하자면 HashSet은 정렬을 지원하지 않는다. 단지 넣은 키값과 HashSet의 테이블의 크기 (정확하게 말하면 크기 - 1)과 & 연산을 진행하여 테이블에 담기게 된다.
코드를 통해서 정확하게 알아보자!
아래 코드의 결과는 무엇일까?
public class WhyHashSetSort {
public static void main(String[] args) {
Set<Integer> hashSet = new HashSet<>();
hashSet.add(4);
hashSet.add(3);
hashSet.add(1);
hashSet.add(2);
hashSet.add(17);
System.out.println(hashSet);
}
}
보기
- [1, 2, 3, 4, 17]
- [17, 1, 2, 3, 4]
- [1, 17, 2, 3, 4]
정답은 무엇일까?
서론의 예시가 정렬이 되었으므로 자연스럽게 1번을 예상할 수 도 있지만
유감스럽게도 답은 3번이다.
왜 17이 1 옆에 있는 걸까?

답은 1과 17은 같은 테이블 인덱스를 가지고 있기 때문이다.
테이블 인덱스를 어떻게 구하는지 모를 땐 아래 링크를 참고하길 바란다.
(JAVA) HashMap은 테이블 인덱스를 어떻게 구하는가?
HashMap에 대한 내용을 공부하다 HashMap의 테이블 인덱스 값을 구하는 과정이 상당히 복잡하다는 것을 알았다. 해당 내용은 쉽게 까먹어버릴 수 있으니 다음번 리마인드를 위해서 더 나아가 많은
jwdeveloper.tistory.com
무슨 말인지 와 닿지 않을 땐 코드를 통해 확인해보자!
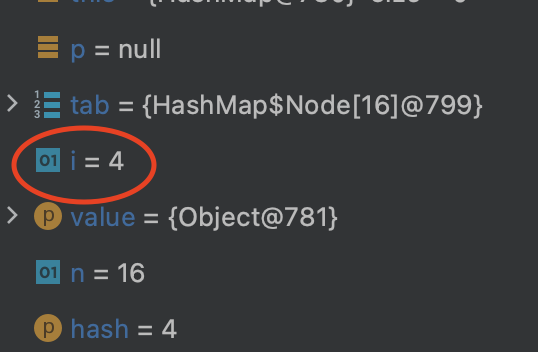
4를 기준으로 디버깅을 해보자!
- 4는 지금 처음 들어가는 값이므로 아무것도 저장된 것이 없다.
- 그러므로 resize를 진행한다.
resize 과정

초기 resize의 경우에는 16개의 노드를 초기화하면서 끝난다. (DEFAULT_LOAD_FACTOR = 16)
final HashMap.Node<K,V>[] resize() {
HashMap.Node<K,V>[] oldTab = table;
/**
* 생략
* */
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
table = newTab;
/**
* 생략
* */
return newTab;
}
4를 넣는 과정

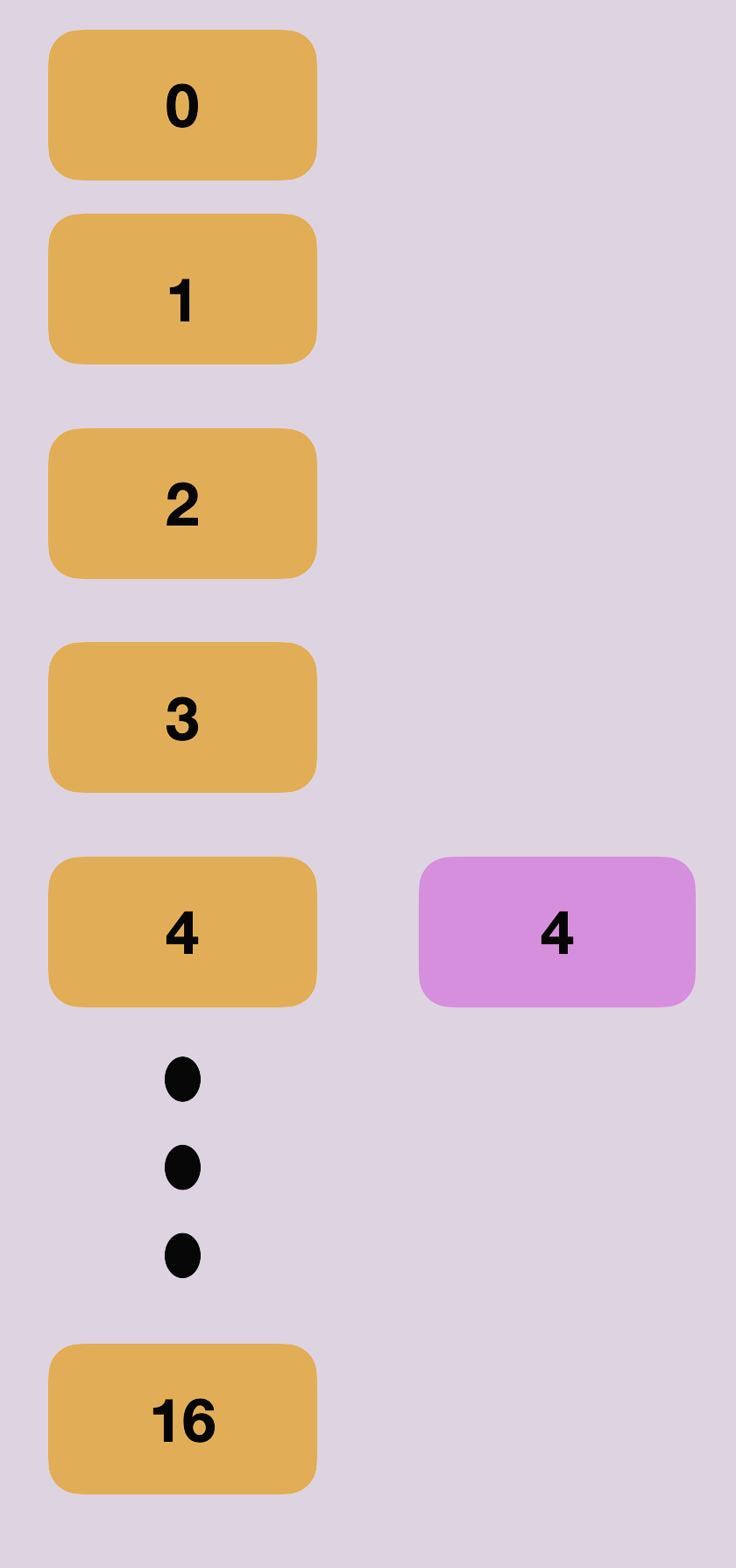
현재 16개의 노드가 만들어졌고
16개의 노드 중 4번째의 인덱스에 4에 대한 노드가 만들어졌고 해당 노드의 첫 번째 값은 4가 되었다.
17을 넣어보자

일단은 3, 1, 2는 위와 같은 작업을 반복하기에 생략하고 17을 넣었을 때 어떠한 현상이 일어나는지를 보자!

위에 보이는 바와 같이 17에 대한 테이블 인덱스는 존재하지 않는다.
tab[i = (n - 1) & hash]위와 같이 테이블 인덱스 값을 구하는데 이에 대한 결과는 1이다.

근데 1은 아까 담겼으므로 1의 다음 이어지는 노드로 17을 담는다.
1 -> 17
아래 코드는 현재 노드에 담겨있는 값을 탐색하며 마지막 노드에 해당 값을 집어넣는 코드이다.
(TREEIFY_THRESHOLD = 8 이에 대한 로직은 다음에 따로 살펴보도록 하자! 지금에 정렬에 초점을 맞추어서!)
/**
* 생략
*/
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
/**
* 생략
*/
그림으로 표현하자면 아래와 같다!

정리
정렬이 되는 것이 아니라 첫 번째 테이블 인덱스부터 순차적으로
1 -> 17
2
3
4
위와 같이 탐색하기 때문에
[1, 17, 2, 3, 4]
결과가 출력되는 것이다.
즉 정렬이 된다는 것은 나의 오해였다!
'Java > Java' 카테고리의 다른 글
| (JAVA) TreeMap은 어떻게 동작하는가? (0) | 2021.02.07 |
|---|---|
| (JAVA) HashMap은 테이블 인덱스를 어떻게 구하는가? (1) | 2021.01.31 |
| (JAVA) CallByValue & CallByReference (0) | 2020.05.17 |
| (JAVA) Garbage Collector (0) | 2020.05.10 |
| (JAVA) Method 오버라이딩에 대해서 (0) | 2020.04.15 |



